【UTAUでお喋り!】その道8年の人間による、HANASU調声のやり方

『HANASU』とは、歌声合成ソフト『UTAU』を使って合成音声によるお喋りを再現することです。
UTAUは本来歌声を作り出すことを目的としたソフトですが、その自由度の高さから『喋らせる』ことも出来ちゃいます。
しかし、正規の使用方法でないだけに初心者がいきなりHANASUをするのはなかなか難しいところも……。

という方に向けて、約8年間(2021年現在)HANASUをやり続けてきた私のHANASUのやり方をご紹介します!
参考になれば幸いです!
デフォルト設定
まず私が普段使っているUTAUのデフォルト設定を紹介します。
主に重要になってくるのは下の画像にある①~③の項目です。
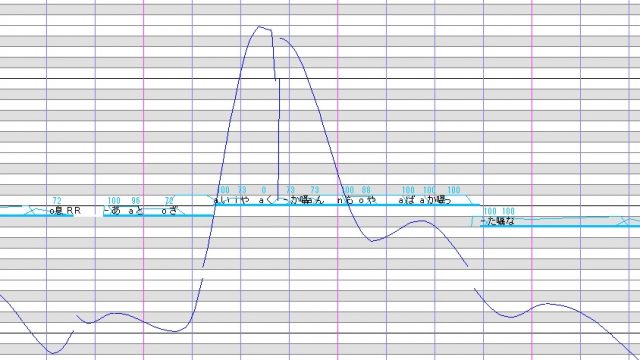
音符のデフォルト設定画面。 UTAU操作画面上部のツール>音符のデフォルト>基本設定で開くことができます。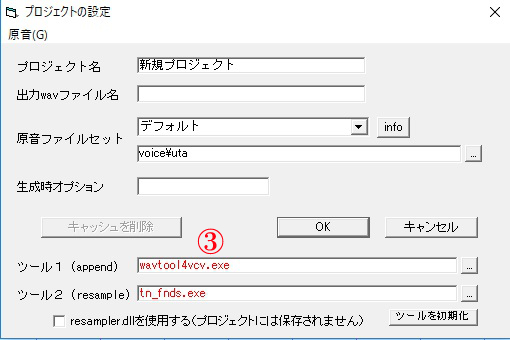 プロジェクトファイルの設定画面。 新規プロジェクトを立ち上げる時に出てくるやつですね。他にもプロジェクト>プロジェクトのプロパティから開くこともできます。
プロジェクトファイルの設定画面。 新規プロジェクトを立ち上げる時に出てくるやつですね。他にもプロジェクト>プロジェクトのプロパティから開くこともできます。①モジュレーション
モジュレーションはピッチの震え具合を調節するパラメータ。
普段はデフォルト値の100に設定しています。
しかし、調声するセリフや使用する音源さんによっては合わないことも……。
その場合は調声作業中に変更します。
経験上、オーバーラップが大きめの音はモジュレーション値が大きいとおかしな音になることが多い印象。
なんでその時はモジュレーション値を低めにするか、0にしてます。
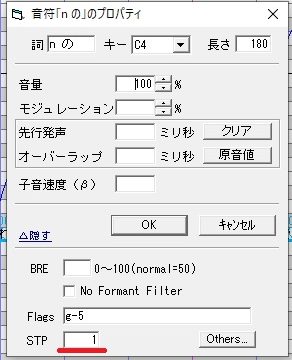
②フラグ
UTAUには声に様々な味付けをするためのフラグがたくさんあります。
デフォルトでは何も追加されていませんが、この音符のデフォルト画面で設定をしておくとピアノロールにノートを打ち込んだ際に自動的に設定したフラグを追加してくれます。便利。
私はgフラグを-5に設定しています。
gフラグとは声の男性っぽさ、女性っぽさを調声できるフラグです。
大体の音源はg-5を入れると私好みの声になってくれるのでデフォルトで入れています。こちらもモジュレーション同様、音源やセリフによっては調声中に変更することもあります。
Ex.春歌ナナや闇音レンリを使う時はg-8にする、高い音のg値は下げる、等。
③エンジン
UTAUにおいて音声を合成する役割を担う部分になるのがこのエンジンです。
デフォルトではUTAUに標準で備えられているresamplerとwavtoolが設定されています。専門的には、resamplerにあたる部分は伸縮器、wavtoolにあたる部分は結合器と呼ばれるんだとか。
エンジンは他にもフリーのものがネット上で公開されています。
私は基本的にtn_fndsとwavtool4vcvの組み合わせで使うことが多いです。セリフや使用音源によってはmoresamplerを使用することもありますね。
同じ音源でもエンジンを変えるとかなり声が変わったりします。興味のある方は色々試して好みのエンジンを探してみてください。
Tempo、Quantaize、Length
ここから調声作業に入っていきます。
今回は例として重音テト音声ライブラリーを使用。
「こんにちは。重音テトです」というセリフを調声していきましょう。
まず始めにTempoを280、Quantaizeを64分音符(またはL96~192)、Lengthを8分音符にします。
 Tempo、Quantize、Lengthの入力欄。UTAU操作画面の左上にあります。より細かくノートの長さを調節したい場合はQuantaizeをL96~L192にするとGOOD。
Tempo、Quantize、Lengthの入力欄。UTAU操作画面の左上にあります。より細かくノートの長さを調節したい場合はQuantaizeをL96~L192にするとGOOD。Tempoは280を基準に、遅く喋らせたい時はより小さく、早く喋らせたい時はより大きく設定していますね。
大体260~300辺りが出番多いです。ごく稀ですが、セリフによっては200とか350くらいを使うことも。
セリフ入力
次にセリフをピアノロール上に打ち込みます。
今回はセリフが「こんにちは。重音テトです」なので、単純に全部ひらがな表記にして「こんにちわかさねてとです」という文字列を打ち込みます。
その後「わ」の後に休符(R)を2個挿入。1個は後に語尾息に変換する用に、もう1個は音を区切る用に入れています。
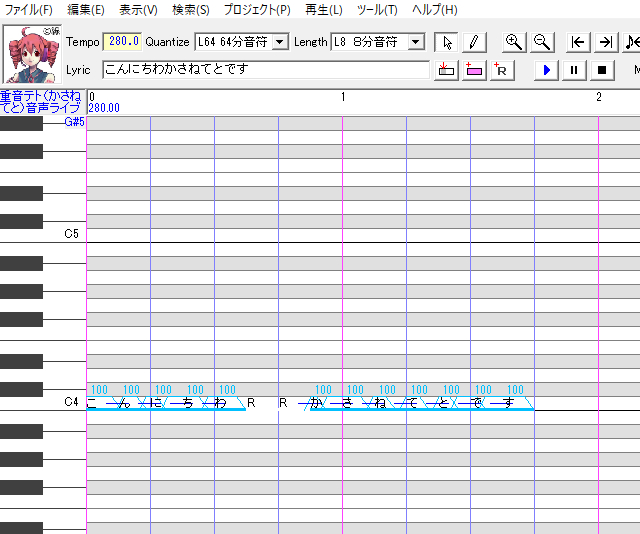 ピアノロール上にセリフが打ち込まれた状態です。画像上部に見える「Lyric」の欄に文字を入力し、その欄の2つ右隣にある「歌詞で挿入」ボタンをクリックして打ち込みます。
ピアノロール上にセリフが打ち込まれた状態です。画像上部に見える「Lyric」の欄に文字を入力し、その欄の2つ右隣にある「歌詞で挿入」ボタンをクリックして打ち込みます。今回は連続音で調声していきますのでプラグインでノートを連続音化し、「わ」の後ろの休符を語尾息に変更。
プラグインは「連続音一括設定」を使用しています。
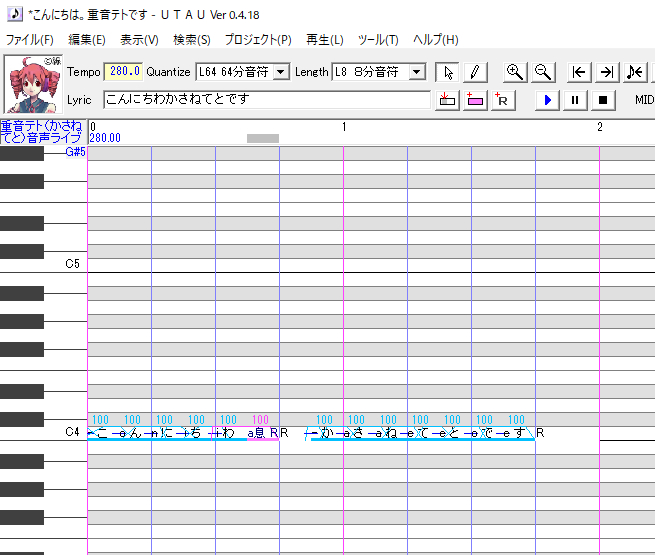 プラグインを使用してノートが連続音になりました。語尾息は休符をShift+右クリックして手動で変更しています。
プラグインを使用してノートが連続音になりました。語尾息は休符をShift+右クリックして手動で変更しています。ノート長
ここからノートの長さを調節していきます。
どのノートをどれくらいの長さにするかは喋り方によって変わってきます。
なので、使用する音源にどのように喋らせたいかを頭の中でイメージしながら調節します。
イメージできないところは実際にセリフを声に出してみると確認しやすいです。
今回は下の画像のようにしてみました。
 ノート長を調声した状態です。文字で表すと「こーんにちはー!かーさねてとでーす!」という感じをイメージしつつ調声しています。
ノート長を調声した状態です。文字で表すと「こーんにちはー!かーさねてとでーす!」という感じをイメージしつつ調声しています。後々微調整するのでこの段階ではざっくりとノート長を決めています。
どうしてもノート長が分からない場合はいったん適当に長さを決めてやります。
例えばノート3つ毎に長くしてみたり、短くしてみたり、といった感じです。
個人的には適当でもノート長に変化があったほうが後の微調整がやりやすいので、わざと変化を付けてます。
ピッチ
続いてピッチを調整していきます。
恐らくHANASU調声において肝になるところですね。
調声の仕方は基本的にノート長の場合と同じです。頭の中でイメージしたり、あるいは声に出して確認しつつピッチ曲線を描いていきます。
今回はこのような感じにしてみました。
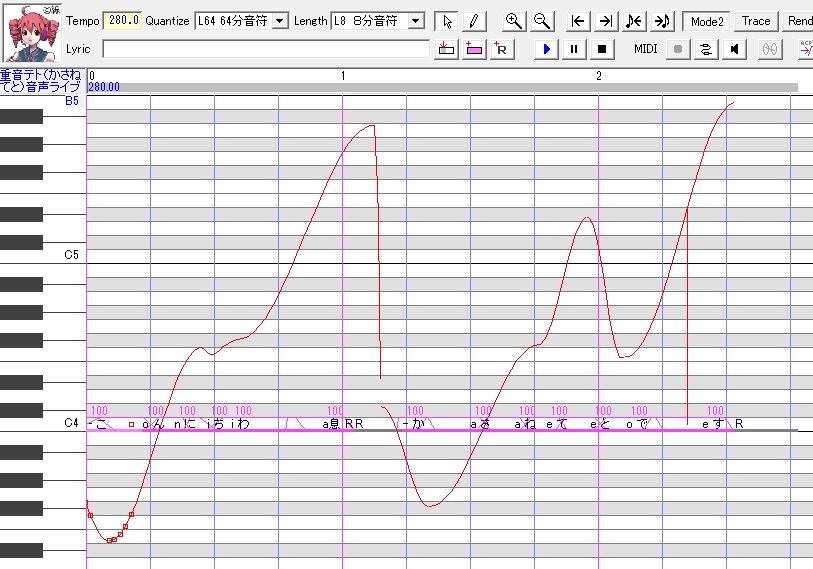 ピッチ曲線を調整した状態の画像です。画像内の赤い曲線がピッチの変化を表しています。
ピッチ曲線を調整した状態の画像です。画像内の赤い曲線がピッチの変化を表しています。ピッチ曲線もノート長と同様、後で微調整しますのでざっくりと描いていきます。
因みに、ここでは拡張ピッチエディタというプラグインを使用してピッチ曲線を描きました。主に曲線ツールを使用していますが、場合によっては直線やフリーハンドで描くときもあります。
 拡張ピッチエディタの操作画面です。このプラグインを活用すればピッチ曲線を自由に、そして直感的に調声できます。
拡張ピッチエディタの操作画面です。このプラグインを活用すればピッチ曲線を自由に、そして直感的に調声できます。ピッチ曲線が分からない場合
初めてHANASUをやる場合は
という方もおられると思います。
また、経験者の方でも調声するセリフによっては
と分からなくなってしまうこともあるでしょう。事実、私も普通にあります。
そんな場合はピッチモニターというソフトがおすすめです。
ピッチモニターとは音声のピッチを表示してくれるソフト。
これを使えば調声したいセリフのピッチを視覚的に確認できます。
で、そのピッチを見ながらUTAUでピッチ曲線を描く、という寸法ですね。
私はスマートフォン用アプリの『ボーカル音程モニター』を使ってます。アプリなら作業の片手間に確認できるのでおすすめ。
パソコン上にUTAUと並べて表示したいという場合はフリーソフトのピッチモニターを使うのもアリです。
ご自身の使いやすいものを探してみて下さい。
最終調整
いよいよ調声作業の最終段階。
ここからはセリフを再生させながら、違和感のあるところを修正していきます。
主に修正するのはノート長やピッチ曲線。
先行発声、子音速度、フラグなどその他のパラメータも必要に応じて変更します。
最終調整をした後の画像がこちらです。
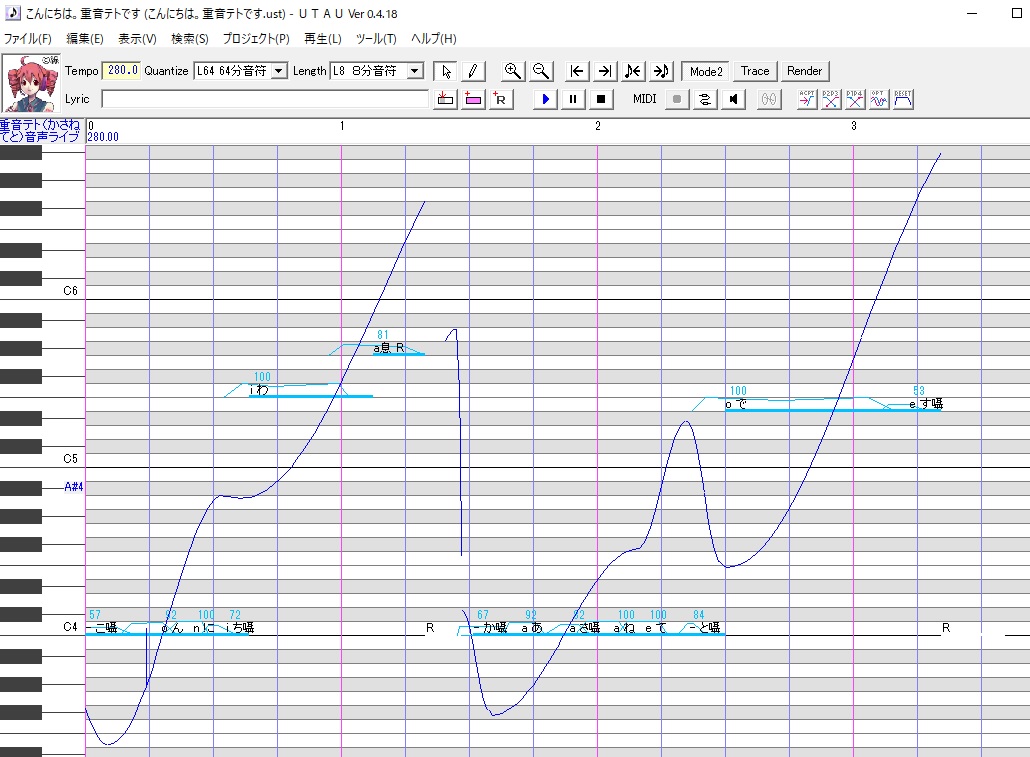 見た目ではそんなに変わっていないかもしれませんが、実はピッチ調声後のものと比べると結構修正しています。
見た目ではそんなに変わっていないかもしれませんが、実はピッチ調声後のものと比べると結構修正しています。最終調整前と変わった部分を簡単に説明していきますね。
①ノートの変更・プロパティ調整
無声音っぽさを出すために「こ、ち、か、さ、と、す」の音を囁き音源に変更しています。
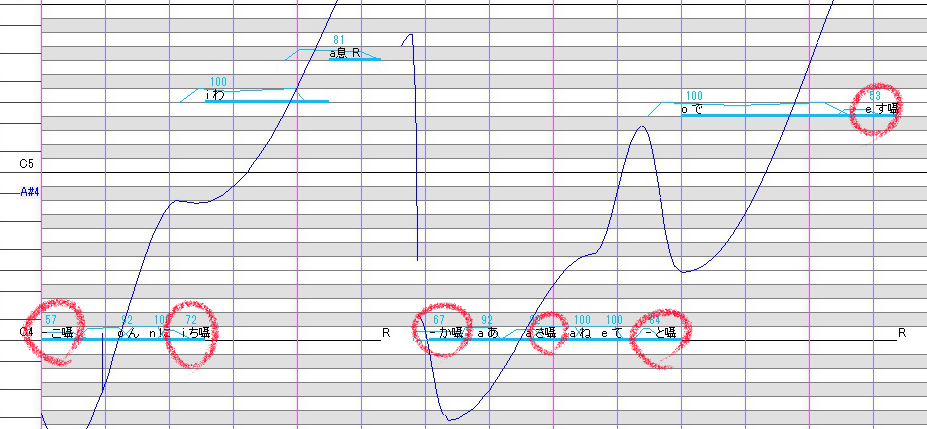 赤い丸印を付けているノートを囁き音源に変更しています。
赤い丸印を付けているノートを囁き音源に変更しています。さらに先行発声と子音速度の値を修正します。今回は大体原音値に対して-60~-30くらいにしています。
参考までに「- こ囁」のプロパティ画像がこちら。
 修正したい対象のノートを右クリック>プロパティか、対象のノートを選択後Ctrl+Eでこの画面を開くことができます。今回のノートでは先行発声の原音値が90だったのでこれを30に、子音速度は全ノート共通でデフォルト値が100なのでそちらを50に修正しています。
修正したい対象のノートを右クリック>プロパティか、対象のノートを選択後Ctrl+Eでこの画面を開くことができます。今回のノートでは先行発声の原音値が90だったのでこれを30に、子音速度は全ノート共通でデフォルト値が100なのでそちらを50に修正しています。無声化すると結構人間っぽい発声になるのでおすすめです。
使用する音源に無声音が用意されている場合はそれを使用すれば大抵問題ありません。
ない場合は今回のように囁き系の音源を使用するか、先行発声や子音速度の値を下げるとそれっぽい音になります。
②ノート長
言葉の最初の部分「こ」と「か」、および最後の「わ」と「で」の部分で長さがイメージと少し違ったので、これらの音を伸ばしてみました。
 赤い線でマークされているノートの長さを伸ばしています。ついでに語尾息も一緒に伸ばしました。
赤い線でマークされているノートの長さを伸ばしています。ついでに語尾息も一緒に伸ばしました。ただ、「か」に関してはそのまま伸ばすと囁き声っぽさが出過ぎてしまったため、後ろに「あ」のノートを追加して音を伸ばしています。
③ピッチ曲線
いつもはここでかなりピッチ曲線を修正することが多いんですが、今回は珍しく最初の調整で大体形が出来ていたのでそんなに弄ってません。細かいところの形を整えたのと語尾をさらに高く持ち上げたくらいですね。
比較しやすいように最終調整前後の画像をもう一度載せておきます。
まずこちらが最終調整前の状態。
そして、こちらが最終調整後の状態です。
 赤く丸で囲っている部分のピッチ曲線を修正しています。
赤く丸で囲っている部分のピッチ曲線を修正しています。また、語尾のピッチを上げたのに合わせて、「わ、息、で、す」の4つのノートの位置も高くしています。
これはUTAUの仕様なのか音源によるものなのか、はたまた私のパソコン環境によるものなのかよく分かっていないのですが、ノートの位置とピッチ曲線の位置が離れ過ぎると、ピッチ曲線の通りの音程で音声が再生されないことがたまにあります。それを防ぐためにノートの位置を変更しました。
④音量、エンベロープ
ここはノート長やピッチ曲線と同様に、自分で声に出してみて音が小さく感じるところの音量を小さくしています。
今回は囁き音源の部分と母音部分の音量をいくらか下げてみました。
エンベロープについては「わ」と「で」に小さく凹みを追加、「息」をフェードアウト、「さ」をよりフェードイン気味に、「て」と「す」の後端部分を削る形で調整してます。
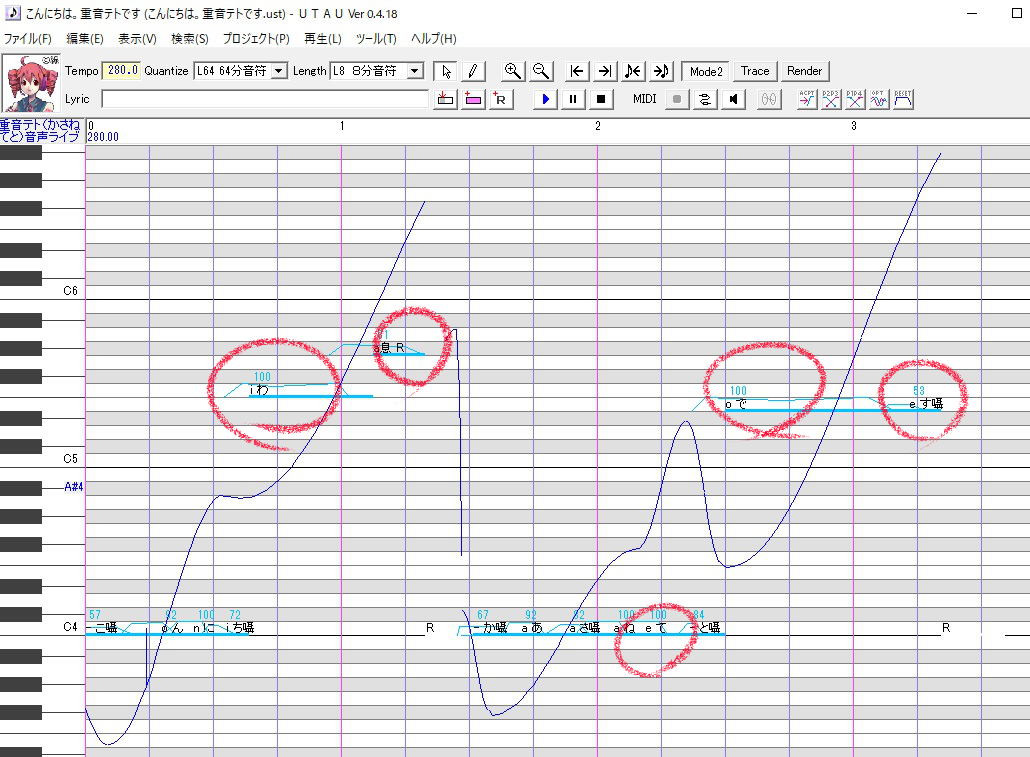 赤丸のノートがエンベロープを調声したものになります。特に最後の「e す囁」はエンベロープの後端を削ることで無声音になるように調声しました。
赤丸のノートがエンベロープを調声したものになります。特に最後の「e す囁」はエンベロープの後端を削ることで無声音になるように調声しました。⑤フラグ
最後にフラグです。今回は語尾のg値をさらに下げました。数値で言うと-20~-10にしています。
経験上、g値は音程が高い部分は小さく、低い部分は大きくすると自然な感じになることが多いです。
比較
大雑把な説明になりましたが、以上が最終調整で変更した部分です。
それでは調声したものを実際に聴いてみましょう!
まずこちらが最終調整前のものです。
これはこれで面白い調声になっていますね。
とりあえず喋っている内容はなんとなく分かるレベルでしょうか。
続いて最終調整したものがこちらです。
実際に聴いてみると結構変わりますね。
最終調整前に比べて不自然さが幾分か軽減されているかと思います。また、元気良さもアップしました。
今回はこれにて調声完了とします!
今回は連続音音源で調声しましたが、単独音やCVVC音源も今回とほぼ同様のやり方で調声できます。
最後に なぜHANASUを選ぶのか、そのメリット
以上が、私が行っているHANASUのやり方です。初めての方にはなかなか難しい内容もあったかも知れません。
実際のところ、合成音声に喋らせる方法はHANASU以外にもあります。
中にはVOICEROIDやSoftalk等、お喋りに特化した音声合成ソフトもあり、ただ喋らせるだけならそれらのソフトウェアを使用するほうが簡単です。
事実、それらの手段と比較するとHANASUにおける調声難易度は明らかなデメリットになります。
にもかかわらず、そのような手段の中からなぜHANASUを選ぶのでしょうか?
それは当然ながら、HANASUを選ぶだけの様々なメリットがあるからです!
以下にHANASUが持つメリットをいくつか挙げておきます。
メリットその1 無料で始められる
UTAUはシェアウェアですがフリーソフトとして使用することも可能で、無料で始めることができます。初心者にとって費用が掛からず気軽に始められるというのはとても大きいメリットです。
しかもほとんどの機能がフリーソフトの状態で使用可能。今回の調声も有料機能は使ってません。無料でここまで出来るなんてめちゃくちゃ有難いですね。
メリットその2 調声の自由度が高い
UTAUは本来歌声を作り出すためのソフトであり、その歌声を調声するために様々なパラメータが用意されています。
そして上記の調声方法を見れば分かる通り、それらのパラメータはお喋りを再現するのにも大活躍します。
そのためHANASUは調声の自由度が高く、様々な喋り方を再現することが可能です。
これは歌唱用の音声合成ソフトならではのメリットですね。
メリットその3 使用できる音源の種類が豊富
UTAUの音源は個人で作成が可能であり、多くの有志の方々がネット上にオリジナルのUTAU音源を公開されています。
なんとその数、数千種類以上もあるとのこと。音声合成ソフトは数あれど、これだけの音源があるソフトは今のところUTAUだけじゃないでしょうか。
この数千種類以上ある音源の中から、自分の気に入った音源にお喋りをさせることが出来る、というのがHANASUの最大かつ独自のメリットです。
以上のように、HANASUにはHANASUなりのメリットが多くあります。特に最後のメリットはHANASUの楽しさにも直結していますね。自分の気に入った音源が自分の好きなように喋ってくれるというのは、思いの外嬉しいものです。
皆さんも是非お気に入りの音源であなただけのHANASUをお楽しみください!
更に踏み込んだ調声についてはこちらの記事でまとめています。



また、YouTubeチャンネルとニコニコ動画にて私のHANASU作品も随時更新中です。ご興味があれば是非ご覧になって下さい!
今回使ったテトさんにSynthesizer V AI版の音源が登場!
早速喋ってもらいました!